币妈妈研究院2021-06-29 17:28:37
Filecoin与IPFS这两个概念常常一同出现,因为它们都是协议实验室Protocol Labs研发的协议,二者是互补关系。IPFS是一个分布式系统,允许用户存储、检索文件、网页、应用和数据;而 Filecoin为这个网络协议提供存储的永续性。Filecoin设计的激励原理是客户付费使用矿工提供的存储空间,而矿工通过持续存储数据、提供证明赚取费用和奖励。
简单来说:IPFS构建点对点的存储网络,Filecoin为它提供奖励机制、吸引参与者。
HTTP协议
我们当前身处的Web 2.0时代,绝大多数的网络数据交流都是通过超文本传输协议(Hypertext Transfer Protocol,即HTTP)完成的。HTTP协议是一个应用层协议,遵循请求-响应的运作方式——客户端发出连接请求,之后服务器处理请求并给出响应。
如果我们想读百度百科对于比特币的介绍,只需要点击或输入它的网址https://baike.baidu.com/item/%E6%AF%94%E7%89%B9%E5%B8%81/4143690?fr=aladdin并等待服务器的响应,得到回复后我们就能浏览这个网页了。
把这个过程分解来看,实际上发生的是两个计算机间的交流,而除了两台电脑外用到的工具还有:传输控制/网络协议(TCP/IP)、网络连接、IP地址、域名(domain name)、域名系统(DNS)、统一资源定位器(URL)、HTTP协议。
· TCP/IP协议是通信协议,它规定了互联网中各部分进行通信的标准和方法。
· 网络连接是保证计算机之间可以通信的渠道。
· IP地址指的是每一台计算机的独特标识码,相当于给网络中每个设备一份编号,用它来认定设备的身份、接受或发送新消息。IP地址一般是由纯数字或数字加字母组成,格式类似172.16.254.1或2001:db8::8a2e:370:7334
· 域名通常指一个网址的顶级域名,是由一串用点分隔的名字组成的、网络上某一台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识。在上文的例子中我们所访问的网站是“百度”,百度的域名是baidu.com,既我们用户在地址栏里真正输入的字符。有了这个域名,我们可以通过网页对应的名称访问网址,而不需要记住复杂的IP地址。
· DNS类似于互联网的地址簿,由于用户输入的域名和计算机本身的IP地址不同,我们需要通过工具将二者联系起来。DNS是将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
· URL包括域名和要访问网页的其他信息(如路径),它也就是我们最终访问该网页时地址栏呈现的字符。上文我们访问的百度百科的域名是baike.baidu.com,而它的路径是item/%E6%AF%94%E7%89%B9%E5%B8%81/4143690?fr=aladdin,因此这个网址的URL是https://baike.baidu.com/item/%E6%AF%94%E7%89%B9%E5%B8%81/4143690?fr=aladdin。
· HTTP协议是基于TCP/IP的应用层,也是传输协议,它是目前WWW中应用最广的协议。
有了这些工具的帮助,现在我们再重新搜索关于比特币的介绍:
1. 我们在浏览器的地址栏输入比特币百科的URL:https://baike.baidu.com/item/%E6%AF%94%E7%89%B9%E5%B8%81/4143690?fr=aladdin,此时DNS会在库中搜索它对应服务器的IP地址;
2. 我们的客户端向服务器发送HTTP请求,要求它给自己发来网页的复制内容;
3. 服务器响应并同意我们的请求,然后将该网站的数据发送到我们客户端的IP地址上;
4. 客户端接收信息并由浏览器将其整合成网页,呈现在我们面前。
如果我们不是已知网页的URL直接访问,也可以通过进入百度域名baidu.com然后搜索的方法打开这个网页,二者的原理是一样的。
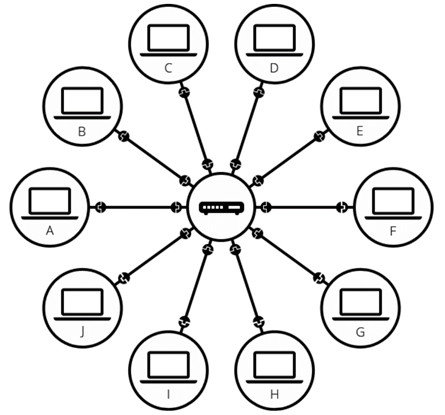
这个过程对于我们用户来说相当简单,那么还有什么地方需要改进吗?有的。
1. 中心化:我们要浏览百度的网页,当然需要触发百度的服务器。那么如果我们想要建立自己的网站,相应的数据也是存储在大公司拥有的服务器中,比如亚马逊、谷歌、百度。而交由单一组织管理的数据总是面临风险与不便。
由于高度依赖中心服务器,一旦服务器被攻击,整个网络会瘫痪无法访问;数据管理方或政府机构可能对文件内容进行审查、修改甚至删除;由于数据从单一服务器传来,且可能距离接收者极远,导致加载内容的速度可能会较慢,让网络的效率变低。
2. 位置寻址:当前的网络文件倾向于通过位置寻址(location addressing)获取,也就通过存储时文件所在的位置来检索的方法。打个比方,我们去图书馆借书时可以通过检索引擎找到我们需要的书的信息,里面包括国际标准书号(ISBN)以及所在藏室、书架等具体位置信息,而位置寻址为我们提供的就是书所在位置的信息。
这种方法虽然可以让服务器快速找到我们要的信息,但无法保证信息的持久性。就像我们在图书馆找到的书一样,也许书中的内容被人做了记号、删减、甚至撕掉了几页,这导致我们无法再看到相应的内容了。位置寻址的弊端就在这里,如果存储的内容(图像、文本、网页、视频等)已经被更改、删除或放弃,它就变得无法恢复。
这两个Web2.0网络的存储特性已经为我们带来诸多不便,如果要解决这些问题就要首先改变存储方式,这也是IPFS协议在做的工作。
IPFS协议
IPFS全称InterPlanetary File System,既星际文件系统。它相较于HTTP协议最大的不同是去中心化存储+内容寻址机制。
去中心化存储vs中心化服务器:
把数据或文件分开存储于不同服务器(节点)解决的不仅仅是安全问题,还消除了用户的隐私困扰。由于每一份数据在存储前都会被多次备份,因此单个节点的崩溃不会让网络的运行受到影响,用户仍然可以从任何存有该内容的特定节点获取数据。此外,由于网络的实际掌控权不再交给某一个或一些机构,他们无法再对数据进行审核、修改、甚至删除,这保证了信息的原始性,同时将数据的使用权交回用户的手中。
内容寻址vs位置寻址:
延续上文的比喻,如果我们根据检索结果提供的位置找到了想要的书,但书的内容被动了手脚,我们看到的信息就不再真实了,因此要确保能够得到真实的数据我们就要掌握内容本身。内容寻址(content addressing)会为每一份存储的文件生成独特的内容标识符(CID),这个标识符基于文件内容的加密哈希,因此一旦内容出现变化CID也会随之变化。当检索时,节点也是通过CID来进行寻找,并且保证找到的信息就是我们真正需要的。它就像是书的ISBN编号,一个编号只能对应一本书的内容。如果后来又发行了这本书的修订版,则不同版次需要有不同的ISBN编号。
尽管目前我们了解了一些IPFS在理念上的创新,但是在这个协议可以被投入使用前还存在一些重要的问题:
这样一个分布式网络需要的节点非常多,那么如何保节点愿意其中呢?
在网络中有了足够的节点后,有什么办法保证节点可以持续存储数据?
对于涉及隐私的内容,IPFS能保证内容仅对CID持有者可见吗?
这些问题现在已经有了答案,那就是IPFS团队研发的Filecoin激励层,它完善了IPFS方案,保证了网络中内容的持久性。也就是说,IPFS确保了内容的更改一定会留下清晰的变更记录,并解决了网址解析失效的问题;Filecoin则通过确保内容的随时获取,来为基于内容的寻址方式提供长久的生命力。

ForesightNews 2022-05-31

DeFi之道 2022-05-31

金色财经 0xOak 2022-05-31

Bress 2022-05-31

元宇宙之心 2022-05-31

达瓴智库 2022-05-30

Cointelegraph中文 2022-05-30

哔哔News 2022-05-30

Unitimes 2022-05-30

NFT中文社区 2022-05-30
币妈妈是一个专注区块链数据分析及讨论交流平台,为数字资产的安全贡献一份力量。
Copyright © 2018-2021 bimama.com All rights reserved.

币妈妈公众号
币妈妈公众号
币妈妈公众号