慢雾科技2022-10-17 20:07:29
点击阅读:EVM 深入探讨 Part 1
导语
在第 1 部分中,我们探讨了 EVM 如何通过被调用的合约函数知道需要运行哪个字节码,其中我们了解了调用栈、calldata、函数签名和 EVM 操作码指令。
在第 2 部分中,我们将开启内存之旅,全面了解合约的内存以及它在 EVM 上的工作方式。
此系列我们将引介翻译 noxx 的文章(https://noxx.substack.com/)深入探讨 EVM 的基础知识。
内存之旅我们依然使用第 1 部分中在 remix 上为大家演示的示例代码。

第 1 部分中我们根据合约编译后生成的字节码研究了与功能选择相关的部分。在本文中,我们将注意力放在字节码的前 5 个字节。

这 5 个字节表示初始化 “空闲内存指针” 操作。要完全理解这些字节码的作用,首先需要理解管理支配合约内存的数据结构。
1、内存数据结构合约内存是一个简单的字节数组,其中数据存储可以使用 32 字节(256 位)或 1 字节(8 位)的数据块存储数据,但是读取时每次只能读取固定大小的 32 字节(256 位)的数据块。下面的图片说明了此结构以及合约内存的读/写功能。
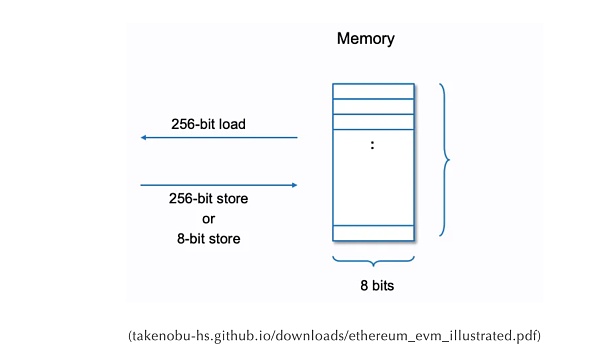
这个功能是由操作内存的 3 个操作码决定的。
MSTORE (x, y):从内存位置 “x” 开始存储一个 32 字节(256 位)的 “y”值。
MLOAD (x):从内存位置 “x” 开始将 32 字节(256 位)加载到调用栈上。
MSTORE8 (x, y):在内存位置 “x” 存储一个 1 字节(8 位)的值 “y”(32 字节栈值的最低有效字节)。
你可以将内存位置简单地看作是开始写入/读取数据的数组索引。如果想写入/读取超过 1 个字节的数据,只需继续从下一个数组索引写入或读取。
2、EVM PlaygroundEVM Playground 有助于巩固我们这 3 个操作码的运行原理、作用以及内存位置的理解。单击 Run 和右上角的箭头进行调试来查看堆栈和内存是如何更改的。(操作码上方有注释来描述每个部分的作用)
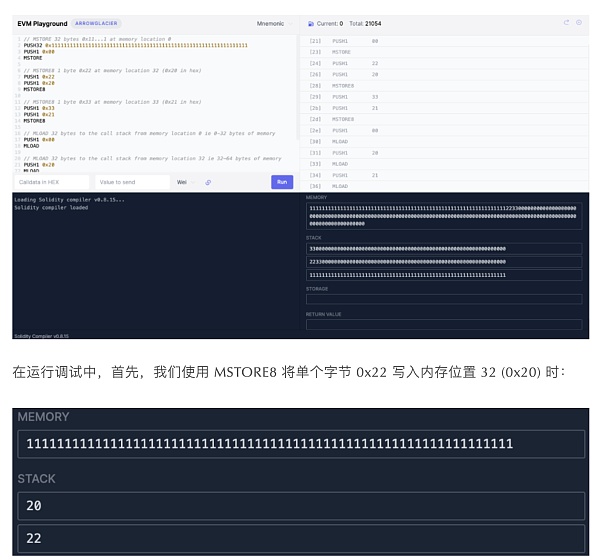

可能会注意到一些奇怪的现象,我只添加了 1 个字节,为什么多了这么多零呢?
3、内存扩展
当合约写入内存时,需要为写入的字节数支付 Gas,也就是扩大内存的开销。如果我们正在写入一个以前没有写入过的内存区域,那么第一次使用它会产生额外的内存扩展开销。
写入之前未触及的内存空间时,内存以 32 字节(256 位)为增量扩展。前 724 个字节,内存扩展呈线性增长,之后呈二次方增长。(由以太坊黄皮书公式 326 扩大内存的 Gas 开销得出,公式为:
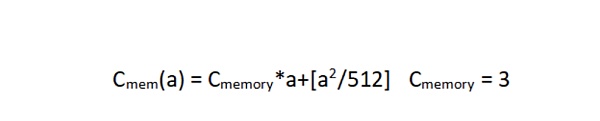
,扩展内存时为每个额外的字的开销。其中 a 是合约调用中写入的最大内存位置,以 32 字节字为单位。用 1024 字节内存为例,那么 a = 32 。)
在位置 32 处写入 1 个字节之前,我们的内存是 32 个字节。此时我们开始往未触及的内存空间写入内容,结果,内存增加了 32 个字节,增加到 64 个字节。内存中所有位置的都初始被定义为 0,这也是为什么我们会看到2200000000000000000000000000000000000000000000000000000000000000被添加到内存中的原因。
4、内存是一个字节数组
调试过程中,我们可能注意到的第二件事发生在我们从内存位置 33 (0x21) 运行 MLOAD 时。我们将以下值返回到调用栈。
3300000000000000000000000000000000000000000000000000000000000000
内存读取可以从一个非 32 字节元素开始。
内存是一个字节数组,这意味着可以从任何内存位置开始读取(和写入)。我们不限于 32 的倍数。内存是线性的,可以在字节级别进行寻址。内存只能在函数中新建。它可以是新实例化的复杂类型,如数组/结构(例如,通过 新建一个 int[...])或从存储引用的变量中复制。
现在我们对数据结构已有了一定的了解了,接下来让我们来看空闲内存指针。
5、空闲内存指针
空闲内存指针只是一个指向空闲内存开始位置的指针。它确保智能合约可以跟踪到哪些内存位置已写入,哪些未写入。这可以防止合约覆盖已分配给另一个变量的某些内存。当一个变量被写入内存时,合约将首先引用空闲内存指针来确定数据应该存储在哪里。然后,它通过记录要写入新位置的数据量来更新空闲内存指针。这两个值的简单相加将产生新的空闲内存开始的位置。
空闲内存指针的位置 + 数据的字节大小 = 新空闲内存指针的位置
6、字节码
就像我们之前所提到的,空闲内存指针是通过这 5 个操作码在运行时字节码的定义的。

这些操作码声明空闲内存指针位于内存中字节 0x40(十进制中的 64)处,值为 0x80(十进制中的 128)。
Solidity 的内存布局保留了 4 个 32 字节的插槽:
0x00 - 0x3f (64 bytes):暂存空间,可用于语句之间,即内联汇编和哈希散列方法。
0x40 - 0x5f (32 bytes):空闲内存指针,当前分配的内存大小,空闲内存的起始位置,初始化为 0x80。
0x60 - 0x7f (32 bytes):插槽 0,用作动态内存数组的初始值,永远不应写入。
我们可以看到,0x40 是空闲内存指针的预定义位置。而值 0x80 只是在 4 个 32 字节保留值插槽之后可写入的第一个内存字节。
7、合约中的内存
为了巩固我们到目前为止所学到的知识,接下来将看看内存和空闲内存指针是如何在 Solidity 代码中更新的。
我们创建 MemoryLane 合约来进行演示。合约的memoryLane()定义了两个长度分别为 5 和 2 的数组,并将 uint256 类型的 1 赋值给b[0]。

要查看合约代码在 EVM 中执行的详细信息可以将其复制到 Remix IDE 中编译并部署合约。调用memoryLane()后进入 DeBug 模式来逐步执行操作码(以上操作可以参考:
https://remix-ide.readthedocs.io/en/latest/tutorial_debug.html)。
将简化版操作码提取到 EVM Playground 中,可通过这个链接查看具体的操作码及注释信息(https://noxx.substack.com/p/evm-deep-dives-the-path-to-shadowy-d6b#:~:text=version%20into%20an-,EVM%20Playground,-and%20will%20run)。
这里将操作码分成 6 个不同的部分依次解读,删除了 JUMP 以及与内存操作无关的操作码同时将注释添加了进去方便查看当前在执行什么操作。
1)空闲内存指针初始化(EVM Playground 操作码代码 1-15 行)

首先,0x80(十进制为 128)先入栈,这是由 Solidity 内存布局规定的值,当前内存中没有任何东西。

最后,我们调用 MSTORE,它将第一项从栈 0x40 弹出以确定在内存中写入的位置,并将第二个值 0x80 作为写入的内容。这样留下了一个空栈,但已经填充了一部分到内存中。内存由十六进制字符表示,其中每个字符代表 4 位。例如:在内存中有 192 个十六进制字符,这意味着我们有 96 个字节(1 字节 = 8 位 = 2 个十六进制字符)。如果我们回顾 Solidity 的内存布局会发现,前 64 个字节将被分配为暂存空间,接下来的 32 个字节将用于空闲内存指针。
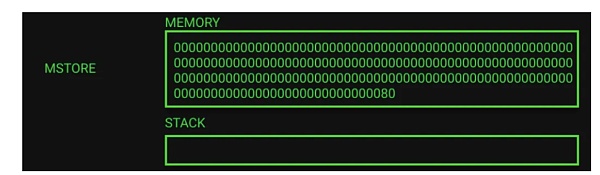
2)内存分配变量 “a” 和空闲内存指针更新(EVM Playground 第 16-34 行)

接下来的部分,我们将跳到每个部分的结束状态,并简洁概述。
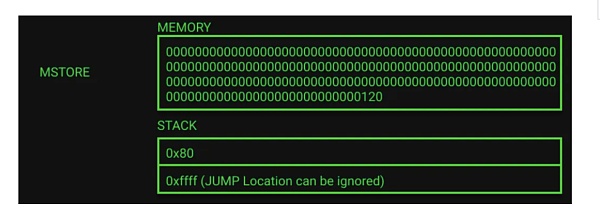
首先,为变量 “a”(bytes32[5])分配下一个内存,并更新空闲内存指针。编译器将通过数组大小和默认数组元素大小确定需要多少空间。Solidity 中内存数组中的元素都是占据 32 字节的倍数(这同样适用于bytes1[],但 bytes 和 string 不适用)。当前需要分配的内存为 5 * 32 字节,表示为 160 或 0xa0(16 进制的 160)。我们可以看到它被压入栈中并添加到当前空闲内存指针 0x80(十进制中的 128)来获取新的空闲内存指针值。这将返回 0x120(十进制的 288 = 128 + 160),我们可以看到它已被写入空闲内存指针位置。调用栈将变量 “a” 的内存位置保存在栈 0x80 上,以便以后可以在需要时引用它。0xffff 代表一个 JUMP(无条件跳转) 位置,可以忽略,因为它与内存操作无关。
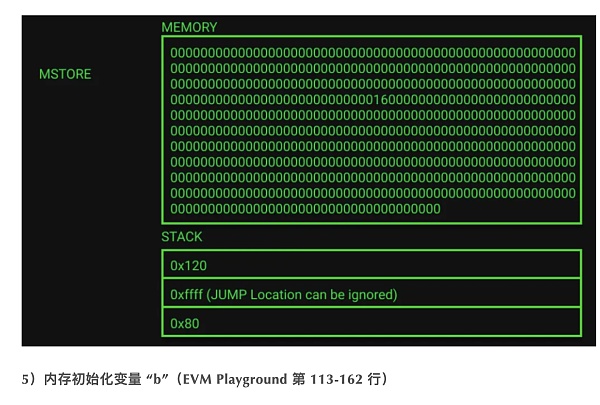
3)内存初始化变量 “a”(EVM Playground 第 35-95 行)


已经分配好了内存并且更新了空闲内存指针,接下来需要为变量 “a” 初始化内存空间。由于该变量只是被声明并没有被赋值,它将被初始化为零值。
EVM 通过使用了CALLDATACOPY(复制消息数据)操作码来进行操作,其中存在 3 个变量。
memoryOffset/destOffset(将数据复制到的内存位置)
calldataOffset/offset(需要复制的 calldata 中的字节偏移量)
size/length(要复制的字节大小)
表达式:
memory[destOffset:destOffset+length] = msg.data[offset:offset+length]
在这个例子中,memoryOffset(destOffset)是变量 “a”(0x80)的内存位置。calldataOffset(offset)是实际 calldata 的大小,因为并不需要复制任何 calldata,所以初始化内存为零。最后,传入的变量为 0xa0(十进制的 160)。
这是可以看到我们的内存已经扩展到 288 字节(这包括插槽 0),并且调用栈再次保存了变量的内存位置和以及栈上的 JUMP 地址。


这与变量 “a” 的内存分配和空闲内存指针更新相同,只是这次是针对 “bytes32[2] memory b”。内存指针更新为 0x160(十进制为 352),等于先前的空闲内存指针 288 加上新变量的大小 64(以 bytes 64 为单位)。空闲内存指针已在内存中更新为 0x160,那么现在在栈上就拥有变量 “b”(0x120)的内存位置。


与变量 “a” 的内存初始化相同。现在内存已增加到 352 字节,栈内仍然保存 2 个变量的内存位置。
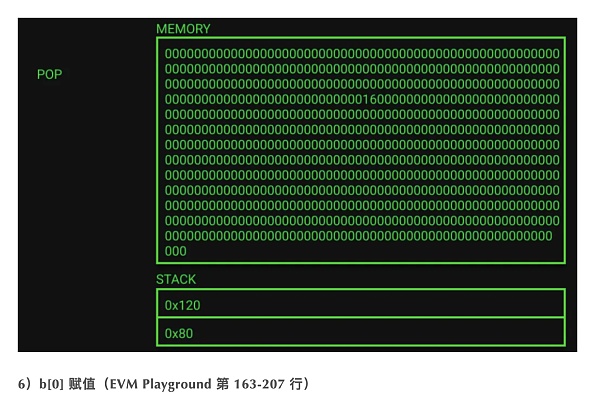


最后,我们开始为数组 “b” 索引 0 赋值。代码指出b[0]的值应该为 1。该值被压入栈 0x01。接下来发生向左移位,但是移位的输入为 0,这意味着我们的值不会改变。接下来,要写入 0x00 的数组索引位置被压入堆栈,并检查该值是否小于数组 0x02 的长度。如果不是,则执行跳转到处理此错误状态的字节码的不同部分。MUL(乘法)和 ADD(加法) 操作码用于确定需要将值写入内存中的哪个位置以使其对应于正确的数组索引。
0x20 (10 进制为 32) * 0x00 (10 进制为 0) = 0x00
需要记住,内存数组是 32 字节的元素,因此该值表示数组索引的起始位置。鉴于我们正在写入索引 0,没有偏移量,也就是从 0x00 开始写入。
0x00 + 0x120 = 0x120 (10 进制为 288)
ADD 用于将此偏移值添加到变量 “b” 的内存位置。偏移量为 0,直接将数据写入分配的内存位置。最后, MSTORE 将值 0x01 存储到这个内存位置 0x120。
下图显示了函数执行结束时的系统状态。所有栈项都已弹出。请注意,实际上在 remix 中还有一些项目留在堆栈上,一个 JUMP 位置和函数签名,但是它们与内存操作无关,因此在 EVM playground 中被省略了。
内存已更新为包含b[0] = 1赋值,在我们内存的倒数第三行,0 值变成了 1。可以验证该值位于正确的内存位置,b[0]应占用位置 0x120 - 0x13f(bytes 289 - 320)。
我们现在对合约内存的工作原理有了一定程度的了解。在后续需要编写代码时,将为我们提供很好理解与帮助。当你跳过一些合同操作码,看到某些内存位置不断弹出 (0x40) ,现在就知道他们的确切含义了。
在本系列下一篇文章中,我们将在 EVM 深入探讨系列第 3 部分深入探讨合约存储的工作原理,了解存储插槽包装(slot packing),揭开存储插槽的神秘面纱。

慢雾科技 2022-10-17

蒋海波 2022-10-17

Biteye 2022-10-17

深潮TechFlow 2022-10-17

蜂巢Tech 2022-10-17

刘教链 2022-10-17

Tang Han 2022-10-17

A16Z 2022-10-17

Odaily星球日报 2022-10-17

元宇宙MetaDaily 2022-10-17
币妈妈是一个专注区块链数据分析及讨论交流平台,为数字资产的安全贡献一份力量。
Copyright © 2018-2021 bimama.com All rights reserved.

币妈妈公众号
币妈妈公众号
币妈妈公众号